
Se dice que “los datos son para una empresa lo que el petróleo para la economía industrial, pero —al igual que el petróleo— se deben procesar, limpiar, analizar y refinar”, y aunque pareciera un cliché, es muy cierto, pero la realidad es un tanto más compleja, según Gartner, 80% de los proyectos de data y analítica que se iniciaron desde 2024 o están iniciando, fallarán, o no cumplirán las expectativas hacia 2027.
¿Cómo puede ser que, con tecnologías muy avanzadas, los resultados no sean los esperados? Para entenderlo, demos un breve recorrido por la historia del procesamiento de datos y descubramos dónde estamos hoy.
Del papel a la inteligencia artificial
En los años 60, en la era de las punch cards, el procesamiento era casi artesanal. Cada tarjeta almacenaba 80 bytes y, en su apogeo, Estados Unidos procesaba 10 millones de tarjetas al día: apenas 800 MB. El data warehouse (DWH) era, en esencia, un registro físico. Casos como el censo estadounidense demostraban que, incluso con limitaciones, los datos podían transformar la forma de gobernar.
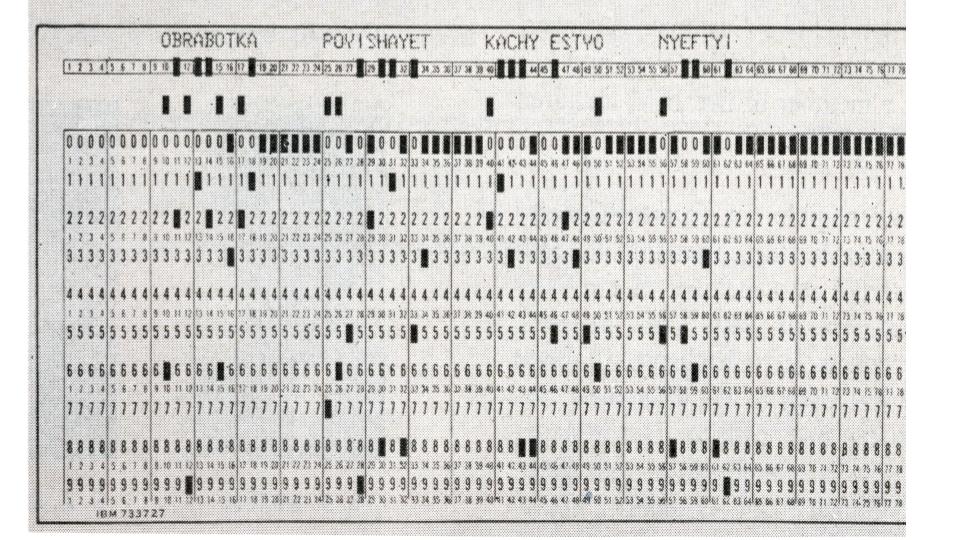
Con la llegada de los años 70, también llegó una revolución en el procesamiento de datos con las bases de datos relacionales y el lenguaje SQL. Oracle V2, lanzado en 1979, permitió realizar consultas estructuradas y análisis más sofisticados. El DWH se convirtió en una colección organizada de datos, aunque con capacidades modestas: apenas unos megabytes.
Así, en los años 80, la popularización de las computadoras personales y las redes locales impulsaron el uso de DMBS. Aparecieron modelos dimensionales y relacionales y Excel se consolidó como “el data warehouse de facto”. Hoy, más de mil millones de personas lo usan, las mismas empresas lo siguen usando, prueba de su vigencia y capacidad.

Con los 90, la explosión digital obligó a las empresas a adoptar arquitecturas más robustas, como ETL, repositorios centralizados y OLAP. Yahoo, Amazon y Netscape marcaron el inicio de una economía basada en datos. El DWH dejó de ser opcional y se convirtió en una prioridad estratégica.
Llegó el año 2000, de la analítica y el procesamiento masivo, en el que con tecnologías MPP como Netezza, Greenplum y Teradata, los DWH alcanzaron escalas de terabytes y respuestas en subsegundos. SAP llegó a registrar el mayor DWH del mundo: 12 petabytes cargando 34 TB por hora. Pero la complejidad y los costos seguían siendo enormes. ¿Entonces?
Hadoop y Spark cambiaron las reglas allá por el 2010, con el big data y la nube, el procesamiento distribuido y el cómputo de memoria, el schema-on-read y la aparición del data lake. La promesa era almacenar todo, pero sin gobierno ni control, esto provocó que muchos lagos se convirtieran en pantanos de datos.
Hoy estamos en la era del lakehouse, la virtualización y la inteligencia artificial embebida. Plataformas como Databricks y Snowflake lideran el mercado, ofreciendo escalabilidad casi infinita y consultas en lenguaje natural. El concepto de artificial intelligence business intelligence (AIBI) redefine la forma en que interactuamos con los datos.
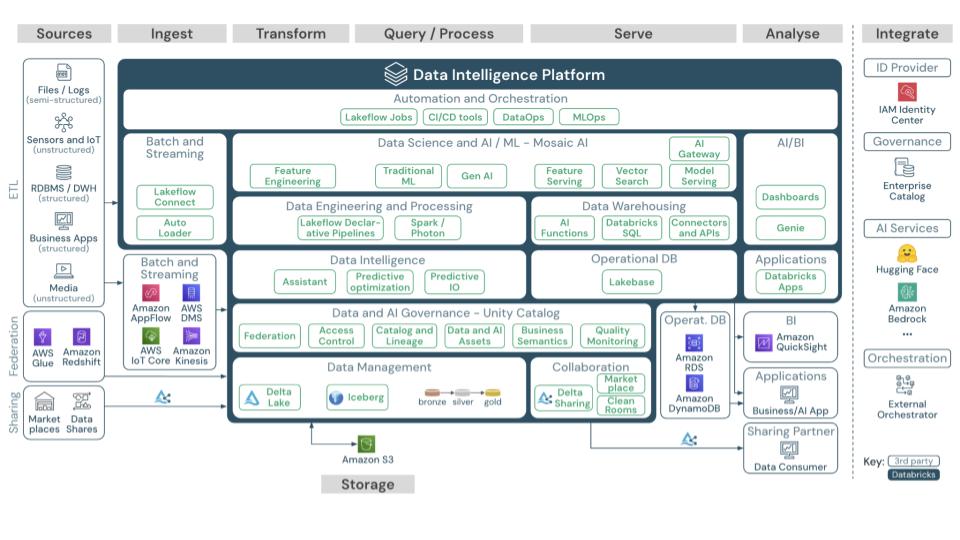
Luego de dar este recorrido por la evolución y la historia del procesamiento de datos, lo cierto es que la tecnología no es el problema, porque ha estado en constante evolución, respondiendo a las necesidades de cada época, el verdadero desafío está en el liderazgo, el enfoque y la colaboración en cada proyecto, así como la visión y abordaje del CIO, porque a lo que nos enfrentamos hoy en día, ya son errores comunes y constantes:
- Falta de involucramiento del negocio: si las áreas operativas no son corresponsables, el proyecto es casi seguro que fallará.
- Expectativas irreales: se exige desplegar en tres meses lo que requiere dos años, sacrificando la calidad y aumentando los costos.
- Equipos sin una estructura de producto: un lakehouse no puede ser una responsabilidad secundaria; necesita visión, roadmap y atención continua.
- Ausencia de enfoque de negocio: sin claridad sobre el “porqué”, los proyectos se convierten en ejercicios técnicos sin impacto real.
Por lo anterior, el CIO tiene una misión clara: habilitar a la empresa para operar con datos de manera sencilla. No se trata de grandes despliegues inmediatos, sino de proyectos concretos, bien definidos y con la corresponsabilidad del negocio. La pregunta no es si invertir en tecnología, sino cómo hacerlo sin perder el control ni depender de “cajas negras”.
En un mundo donde los datos son poder, la diferencia entre el éxito y el fracaso de un proyecto está en la estrategia, en trabajar con partners. Porque, al final, la tecnología es solo la herramienta; el verdadero valor lo generan la visión y la ejecución.
En Vinkos, trazamos contigo estrategias que harán que tu proyecto marque la diferencia entre el éxito y el fracaso. Síguenos en LinkedIn y acércate a nosotros.







